
Leveraging blockchains and storage networks as a data interoperability layer#
Author: Brandon Ramirez
For decades, the only widely used database in town was the SQL database, and it still lies at the heart of most of organizations, software applications, and institutions. With the advent of the blockchain, however, there is finally an alternative to the relational database, and I’m not just talking about the incremental improvements brought about by the NoSQL movement. We’re on the cusp of a new paradigm, dubbed the decentralized web or Web3, where data, rather than proprietary APIs, is the fundamental substrate for interoperability. In this post, I explain why this transition is happening, and how the GraphQL query language is uniquely positioned to power this new era of data interoperability.
The problem with proprietary APIs#
The web of today is connected via proprietary application programming interfaces (APIs), which exist mainly to solve the limitations of a centralized, typically SQL, database. In describing the state of affairs, Vinay Gupta, previously of the Ethereum foundation, observed:
When you’ve got a single big database at the heart of your organization, which stores all truth and all wisdom, you’re very reluctant to let other people touch that database.
So, proprietary APIs running on servers act as a protective barrier to a central database. They limit what goes in, what goes out, by whom, and in what format. With the microservices pattern, we even encapsulate data within organizations, such that services built by different teams must go through one another’s APIs. While this has gotten us to where we are today, this proliferation of APIs has the following drawbacks:
- APIs are rigid and costly to maintain.
- The current model is inefficient.
- Proprietary APIs lead to data monopolies.
Let’s examine each of these more closely.
1. APIs are rigid and costly to maintain#
APIs, specifically REST APIs (more on this later), are designed with specific use cases in mind, such as a feature in a web app, and the further you get from those use cases, the more difficult they become to use.
Within organizations, this leads to an ever-expanding API surface area. Each new feature requires additional engineering work to extend the API with a new endpoint. Each new endpoint, in turn, requires ongoing engineering work to maintain and support for the duration of its usage, which can be a very long time.
For consumers of public APIs, meanwhile, they are stuck with the use cases that the API developers decide to support. Kyle Daigle, Github’s Director of Ecosystem Engineering, stated the issue clearly:
Almost every API drives integrations by its design… every API I can think of… they all have sort of an idea of how they want you to use it, and if you want to subvert that, it’s basically impossible……you have to go and scrape a ton of database, stick it in a database, and essentially build your own API around that.
The rigidity of these public APIs requires a ton of extra engineering effort to work around, which brings us to our next point.
2. The current model is inefficient#
As we’ve seen, the rigidity of APIs leads to a proliferation of more databases and APIs, often to store the exact same data, simply in a different format or behind different API semantics. Each of these new databases and APIs requires additional infrastructure and engineering resources to maintain.
It also leads to an incredible amount of indirection. Again, quoting Vinay Gupta on the topic:
When you file a form with the IRS, it goes through 6 or 7 processes before it winds up in their databases… the whole collaboration [is] indirect, bureaucratic, difficult.
In their paper describing this problem in the context of research data, Brendan O’Brien and Michael Hucka describe the primacy of the SQL database as the “database in the middle” pattern, shown below:

_“Database in the middle pattern” adapted from: https://qri.io/papers/deterministic_querying/_
Any sufficiently non-trivial software system will involve countless servers encoding data from one database, serving it over the network, decoding the data, putting it in another database, and repeating this process many times over.
O’Brien and Hucka go on to describe how it’s common in these data pipelines for the intermediate results to be stored in a private database or thrown out entirely because of the engineering effort required to make this data publicly available. The result is two dimensions of duplication: within data pipelines and across data pipelines created by isolated teams and organizations.
3. Proprietary APIs lead to data monopolies#
The necessity of placing data in silos also leads to moral hazard. It has become a common narrative in the tech scene, where a major tech giant revokes access to its proprietary APIs after previously encouraging developers to build on their platform.
Facebook did it intentionally to stifle competition, and Twitter did it to monetize it’s data more effectively. InfoWorld’s Senior Writer, Serdar Yegulalp, covered Twitter’s story, succinctly describing the risks of building on proprietary APIs:
"Call it one of the occupational hazards of the API economy: The more widespread and multifaceted the reliance on a single entity — be it as a data source, an analytics layer, or an infrastructure — the easier it is to have the rug yanked out from under your feet."
A software architecture paradigm that requires data to sit behind gatekeepers naturally invites the pernicious practices of these data monopolies.
Lest I be too unfair, I should note that API-based connectivity has been a massive success. APIs have created immeasurable economic value by enabling developers to compose software from smaller purpose-built services like Stripe or Twilio. They’ve given us a way to safely transmit data between applications in the legacy technology landscape dominated by SQL. The internet we know and love today would not be what it is without APIs. But now, with the advent of blockchain and other web3 technologies, we have a chance to enter a new era of frictionless interoperability on the internet.
Enter blockchain and content-addressed storage#
At the heart of the shortcomings of SQL as well as most NoSQL databases is its embrace of an information model that mutates data in place. Rich Hickey, creator of the Clojure programming language and the Datomic database, calls this place-oriented programming (PLOP), and while it was necessary once to overcome the limitations of small memory and disk size, it no longer has any place in a modern information model. When data can be changed in-place in arbitrary ways, it’s impossible to trust that the data is correct or hasn’t changed under your feet since the last time you accessed it. So, it’s not surprising that two of the enabling technologies of the decentralized web, blockchain and content-addressed storage, both emphasize immutability in their information models.
Content-addressed storage#
While blockchains have far more buzz, I’ll begin by explaining content-addressed storage as it is the simpler and more fundamental concept. The idea is this: for any piece of data — an entity in a database, a file in a filesystem, a blob on a CDN — how do you reference that data? Do you give it an arbitrary ID, a URL, or a name, which can refer to different data at different times, depending on how you ask… or, do you give it a unique ID that will always and forever resolve to a specific value, no matter where it’s served from — locally on your own file system, on a remote server, or from another planet?
Content-addressed storage networks, such as the Interplanetary File System (IPFS) or the distributed version control system Git, take the latter approach, using IDs that are uniquely computed (using a hash function) from the content itself. Because a content ID should always return the same content, which can in turn be used to re-compute the ID, verifying the integrity of data is trivial.
At this point, you may be asking yourself, if content-addressed storage is immutable, then how can we do anything useful with it? After all, the things in the real world we use data to represent — your bank account balance, your friend list, your todo list— change over time. How can we represent concepts that change over time using immutable data as the core building block? This is where blockchains come in.
Blockchains#
A blockchain, at its core, is an append-only data structure of immutable values — a chain of blocks. While each block is immutable and unchanging, we may mimic mutability by having variables, such as account balances or smart contract state, differ in value from block to block. From this pattern, we get auditability for free, meaning we can see how any variable has changed over time, allowing external processes to directly depend on this data with confidence.
Blockchains with smart contract capabilities, such as Ethereum, also give us a way to codify how a piece of data can be modified, and by whom, in a way that is secure — a responsibility that has typically been the purview of centralized APIs.
Both these innovations open up a new paradigm where data stored on blockchains and content addressed networks acts as the interoperability layer:
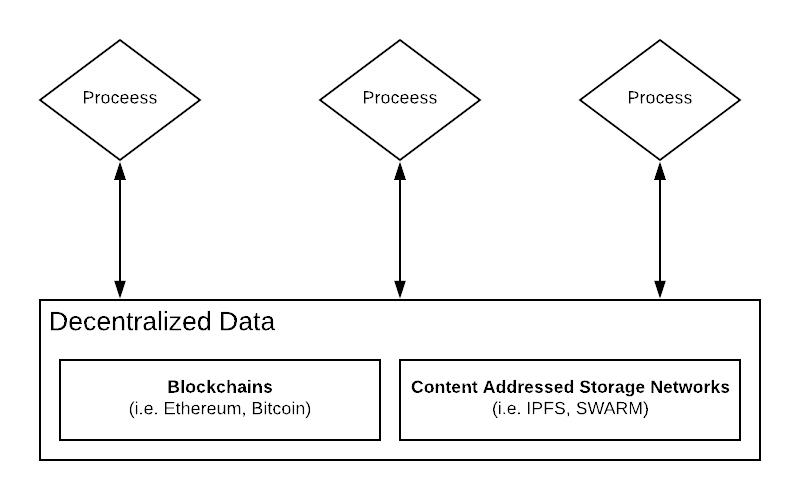
Decentralized data as an interoperability layer
Because blockchains are designed to be decentralized, permissionless, and operate in adversarial environments, there is no need for them to be hidden behind some extra protective layer to be secure and robust. For data living in blockchains or content-addressed storage networks, proprietary APIs are no longer an architectural necessity — processes can interact directly with decentralized data as a shared substrate for interoperability.
Querying decentralized data#
If blockchains are a new type of database primitive, then how will we query that data? Will it be through RESTful APIs, RPC calls, SQL interfaces? The answer will inevitably be all the above, but for decentralized applications that aim to deliver consumer-grade performance built atop blockchain, GraphQL is the natural choice.
GraphQL is more efficient than REST or RPC APIs#
GraphQL is both a query language and interface definition language (IDL) and was invented and open-sourced by Facebook. It was designed to overcome the rigidity and inefficiency of traditional RESTful APIs, which we previously discussed in this post. It does this by exposing a powerful, yet ergonomic, query language directly to consumers of an API.
With traditional REST (Representational State Transfer) APIs, each entity or resource has a separate endpoint that defines the data you will receive about that entity. For example, to get the name of the organization a user belongs to, you might have to first make a call to:
/api/v2/users/1
And then a call to:
/api/v2/organizations/7
A real-world application built on traditional APIs might make dozens or hundreds of round-trip network calls. And, this isn’t just a problem for REST. AdChain, a popular decentralized application, builds on the Ethereum RPC API and is forced to make hundreds of round-trip network calls to Infura to load its UI, resulting in a congested network and suboptimal load times.
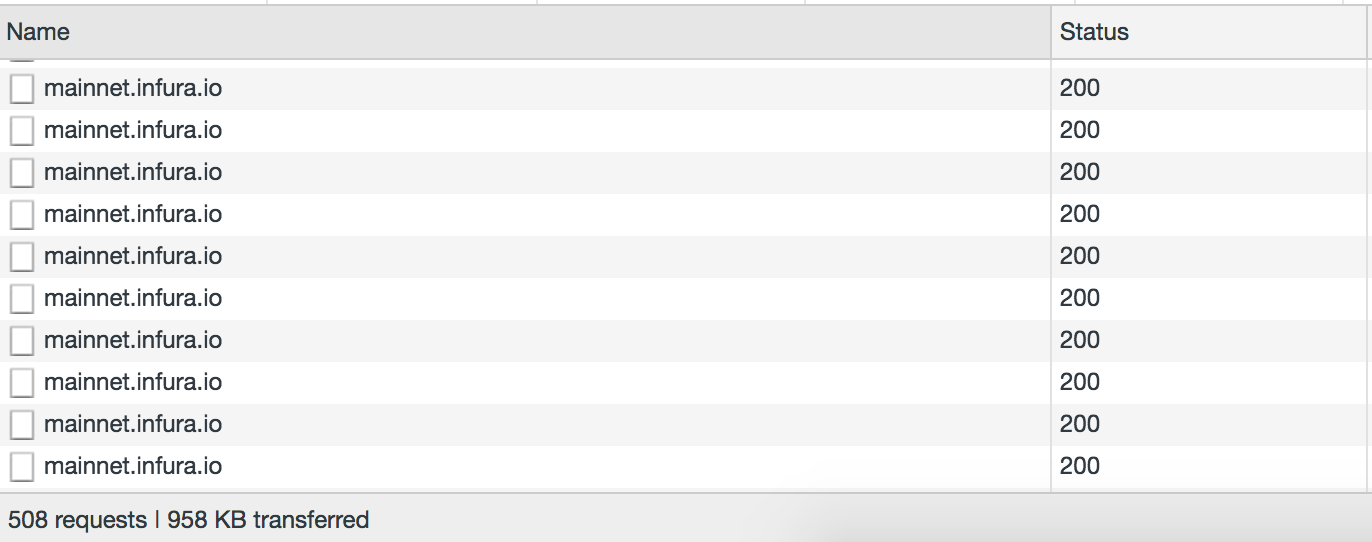
Hundreds of network calls to Infura made by the AdChain registry, as of this writing: https://publisher.adchain.com/domains
GraphQL, on the other hand, is powerful enough to express all the data an application requires in a single query. No matter how much data you need, with GraphQL you never need to make more than one network call. This is sometimes referred to as solving the under-fetching problem. Furthermore, you only get exactly the data you asked for and no more, thus addressing the over-fetching problem.
The result is interfaces, which are far less opinionated on how they are consumed, give you only the data you want, and don’t require constant updating to support new use cases by external developers.
GraphQL is better than SQL for decentralized applications#
But why not use another query language, such as SQL, to query data blockchains as some have called for?
To be clear, I think this can and should happen. SQL has wide adoption worldwide, is familiar to millions of developers, and is strictly more powerful than GraphQL as a query language. It is particularly familiar to data scientists and data engineers, who may be unfamiliar with GraphQL. That being said, SQL will not be the language preferred by decentralized applications (dApps) building on blockchain.
There are a few main reasons GraphQL will win over SQL for dApps built on blockchain:
- GraphQL is “powerful enough”
- GraphQL is more ergonomic for front-end developers
- GraphQL was designed to be consumed across organizational trust boundaries
Let’s dive in.
1. GraphQL is “powerful enough”#
Even though the GraphQL query language isn’t natively as expressive as SQL, a well-designed GraphQL endpoint can be designed to give you most of the querying capabilities you expect from an SQL query interface. For example, the GraphQL spec doesn’t natively specify a way to do aggregations, but standards such as OpenCRUD have emerged that specify how to expose this functionality.
There is still some long-tail functionality, such as ad-hoc joins across entities, that will likely always be out of reach for a GraphQL API. However, I estimate that for 99.9% of the use cases needed for front end applications, GraphQL is good enough.
2. GraphQL is more ergonomic for front-end developers#
For what little you give up in power by choosing GraphQL, you get back in ergonomics. For example, GraphQL has a familiar JSON-like syntax:
query {
user(id:1) {
name
organization {
name
}
}
}And, the response of a GraphQL query is a JSON object that exactly mirrors the shape of the request.
{
"user": {
"name": "Vitalik",
"organization": {
"name": "Ethereum Foundation"
}
}Given that JSON is the most commonly used data format for transmitting data on the web, this syntax is incredibly approachable for most web developers.
The equivalent SQL query, meanwhile, would look like:
SELECT user.name, organization.name
FROM user JOIN organization ON (user.organization_id=organization.id)
WHERE user.id=1Not the worst thing to look at, but it’s arguably less straightforward than the GraphQL query.
And, the response data would be denormalized and tabular, sent in the proprietary wire protocol of the specific SQL database you happen to be using. This is in contrast to the intuitive nesting of the GraphQL response, expressed as plain-text JSON sent over HTTP.
The GraphQL ecosystem, also has tooling, such as React-Apollo, which makes it incredibly simple to integrate data fetched via GraphQL directly into UI components of web applications. Since SQL is almost never consumed via HTTP directly from mobile or web applications, no such tooling exists in the SQL ecosystem that I’m aware of.
3. GraphQL was designed to be consumed across trust boundaries#
Perhaps more importantly, SQL endpoints were never designed to be consumed across organizational trust boundaries. For example, if we’re using SQL to supply read-only blockchain data, an overly complex SQL query is sufficient to bring your database to a crawl, making it unusable for anyone else.
GraphQL is also powerful enough to trigger arbitrarily expensive computations on your backend, however, unlike SQL, tackling this problem has been an area of focus from day one, and there is a growing body of research and tooling to enable dynamically blocking expensive queries and throttling clients.
Meanwhile, the analogous approach to solving this problem in SQL has traditionally been to manually find the slow queries and simply rewrite them. Alternately, one might add indexes or change the database schema to lessen the impact of the “approved” expensive queries. That’s the nature of how SQL has always been deployed in organizations, with only a tightly controlled group of people or services able to query an endpoint directly.
Another place where GraphQL’s cross-organizational DNA shines is in its schema introspection. GraphQL treats schema introspection as a first class concern of the language.
For example, the Root type in GraphQL has a _schema field that can be used to introspect the types that are available to query:
// GraphQL request
query {
**schema {
types {
name
description
fields {
name
}
}
}
}// JSON response
{
"data": {
"**schema": {
"types": [
{
"name": "Root",
"description": null
},
{
"name": "User",
"description": "A user of the platform."
"fields": [
{ "name": "name" },
{ "name": "id" }
]
},
{
"name": "Organization",
"description": "An organization of the platform."
"fields": [
{ "name": "name" },
{ "name": "id" }
]
}
]
}
}
}In fairness to SQL, while some introspection queries can look truly horrific, a mostly analogous introspection to the above doesn’t look terrible if you’re familiar with the syntax:
SELECT c.table_schema,c.table_name,c.column_name,pgd.description
FROM pg_catalog.pg_description pgd
RIGHT JOIN information_schema.columns c on
(pgd.objsubid=c.ordinal_position)
WHERE c.table_schema NOT IN ('pg_catalog', 'information_schema');However, this SQL query is full of vendor-specific parameters for a Postgres database. The equivalent query for a MySQL database would be different. Also, while the above query is easy enough to read as plain text, sending that query and receiving a response, requires special tooling — a vendor-specific CLI client or a cross-vendor Desktop GUI, which understands the vendor-specific SQL flavors, wire protocols, ODBC, or some combination of the above.
GraphQL, on the other hand, returns plain text JSON over HTTP for all queries, including introspection queries, so that you can kick the tires on an endpoint with Postman, Chrome Dev Tools, or the simple curl command that comes preloaded on every Mac and Linux OS terminal.
Conclusion#
It’s true that many of the shortcomings of REST and SQL that I’ve highlighted are not without remedy. There have been efforts to solve over-fetching and under-fetching problems with RESTful APIs. There have been efforts to add schemas to RESTful APIs, which theoretically could be served from a predefined endpoint. SQL is also just a query language, not an implementation, and so, nothing stops us from building an SQL interface that uses HTTP, returns plain text CSV or JSON over the wire, and has more sensible introspection capabilities. However, efficiently querying for arbitrary data directly, across organizational trust boundaries as blockchain and content-addressed storage networks have now enabled, is simply not in the DNA of either of these two technologies.
GraphQL, meanwhile, was designed from the ground up for this use case. It was designed with front-end engineers in mind with user-friendly GUIs for advanced introspection and mature tooling that makes it nearly seamless to declaratively bind GraphQL queries to UI components in the browser. In a paradigm where dApps primarily consist of browser apps interfacing with smart contracts running on a blockchain, the needs and preferences of front-end engineers will be a driving force in determining the technology stack of the decentralized web. It’s why we’re already seeing multiple efforts to put a GraphQL interface in front of Ethereum’s JSON RPC API.
At The Graph, we believe that building rich user experiences with consumer-grade performance, on top of blockchains, is one of the primary hurdles to achieve widespread adoption of blockchain and the decentralized web. It’s why last July we open-sourced an indexing server that allows developers to efficiently query Ethereum and IPFS data for their decentralized applications via a GraphQL interface. In the future, as analytics pipelines for data science and machine learning on blockchain become a more common use case, we will look at supporting SQL and, perhaps, other query languages as well… Datalog, anyone?
Source: GraphQL Will Power the Decentralized Web from Medium