
作者: 丁沛灵(ArcBlock 软件工程师)
导读#
以太坊虚拟机(Ethereum Virtual Machine)是以太坊的基础,它负责执行所有的交易(Transaction),并且根据这些 Transaction 来维护整个以太坊的账户状态,或者更准确的称之为 World State。Transaction 分很多种,有最简单的以太币(Ether)交易,有部署或者调用智能合约的交易。智能合约(Smart Contract)是由虚拟机执行的代码,用以完成复杂的业务逻辑。Solidity 是目前最流行的编写智能合约的高级语言。由 Solidity 编写的智能合约会先被编译成可被虚拟机直接接受的字节码,然后会被用户以 Transaction 的方式发送给以太坊从而进行智能合约部署。在这之后,用户便可以调用智能合约的函数来完成业务逻辑。那么在整个流程中,Solidity 代码是如何被编译成字节码的?字节码在虚拟机中又是如何运行的?编译字节码的时候,虚拟机如何对其进行优化?本期 ArcBlock 工程博客将带你一起,详细剖析这些问题。
从一个例子开始#
让我们从一个最简单的智能合约例子开始。
pragma solidity ^0.4.11;
contract C {
uint256 a;
function C() {
a = 1;
}
}这段代码非常类似 Java,为了简单起见,在这里我就借用一下 Java 的术语。这段智能合约有一个成员变量a,其类型是一个 256 位的无符号整型数。另外,它还有一个构造函数,在其中我们将成员变量a赋值为 1。下面让我们来编译这段代码,我们有两个工具可以用来编译代码:
solc --bin --asm file_name.sol- http://remix.ethereum.org
第一个是一个命令行工具,大家需要先自行安装。第二个是一个强大的网页版 IDE,它可以快速的编译,部署以及调试智能合约。编译后的代码我们称之为字节码(bytecode),如下所示:
60606040523415600e57600080fd5b600160008190555060358060236000396000f3006060604052600080fd00a165627a7a72305820d315875f56b532ab371cf9aa86a62850e13eb6ab194847011dcd641b9a9d2f8d0029在这段字节码中,每个字符代表一个 16 进制数,每两个字符代表一个字节。这段字节码就是直接运行在虚拟机上的代码,虚拟机只需要按照事先定义好的规则,解释并且执行每个字节即可。但是对人类来说,直接阅读这些字节码太过繁琐,所以我们可以将其转换成对人类更友好的形式,操作码(OpCodes),如下所示:
PUSH1 0x60 PUSH1 0x40 MSTORE CALLVALUE ISZERO PUSH1 0xE JUMPI PUSH1 0x0 DUP1 REVERT JUMPDEST PUSH1 0x1 PUSH1 0x0 DUP2 SWAP1 SSTORE POP PUSH1 0x35 DUP1 PUSH1 0x23 PUSH1 0x0 CODECOPY PUSH1 0x0 RETURN STOP PUSH1 0x60 PUSH1 0x40 MSTORE PUSH1 0x0 DUP1 REVERT STOP LOG1 PUSH6 0x627A7A723058 KECCAK256 0xd3 ISZERO DUP8 0x5f JUMP 0xb5 ORIGIN 0xab CALLDATACOPY SHR 0xf9 0xaa DUP7 0xa6 0x28 POP 0xe1 RETURNDATACOPY 0xb6 0xab NOT 0x48 0x47 ADD SAR 0xcd PUSH5 0x1B9A9D2F8D STOP 0x29上面的字节码或者操作码是等价的,它们都可以被分为三个部分:
- 部署智能合约的代码
60606040523415600e57600080fd5b600160008190555060358060236000396000f300
PUSH1 0x60 PUSH1 0x40 MSTORE CALLVALUE ISZERO PUSH1 0xE JUMPI PUSH1 0x0 DUP1 REVERT JUMPDEST PUSH1 0x1 PUSH1 0x0 DUP2 SWAP1 SSTORE POP PUSH1 0x35 DUP1 PUSH1 0x23 PUSH1 0x0 CODECOPY PUSH1 0x0 RETURN STOP</br>
- 智能合约本身的代码
6060604052600080fd00
PUSH1 0x60 PUSH1 0x40 MSTORE PUSH1 0x0 DUP1 REVERT STOP</br>
- Auxdata
a165627a7a72305820d315875f56b532ab371cf9aa86a62850e13eb6ab194847011dcd641b9a9d2f8d0029
LOG1 PUSH6 0x627A7A723058 KECCAK256 0xd3 ISZERO DUP8 0x5f JUMP 0xb5 ORIGIN 0xab CALLDATACOPY SHR 0xf9 0xaa DUP7 0xa6 0x28 POP 0xe1 RETURNDATACOPY 0xb6 0xab NOT 0x48 0x47 ADD SAR 0xcd PUSH5 0x1B9A9D2F8D STOP 0x29</br>
下面让我们来逐步讲解每个部分,看看它们都是怎么工作的。
1. 部署智能合约的代码#
第一部分代码是事实上把智能合约部署到以太坊上的代码,也是我们重点讨论的部分。这段代码又可以被划分为三个部分:
- Payable 检查
60606040523415600e57600080fd
PUSH1 0x60 PUSH1 0x40 MSTORE CALLVALUE ISZERO PUSH1 0xE JUMPI PUSH1 0x0 DUP1 REVERT</br>
- 执行构造函数
5b6001600081905550
JUMPDEST PUSH1 0x1 PUSH1 0x0 DUP2 SWAP1 SSTORE POP</br>
- 复制代码,并将其返回给内存
60358060236000396000f300
PUSH1 0x35 DUP1 PUSH1 0x23 PUSH1 0x0 CODECOPY PUSH1 0x0 RETURN STOP</br>
1.1 Payable 检查#
payable是 Solidity 的一个关键字,如果一个函数被其标记,那么用户在调用该函数的同时还可以发送以太币到该智能合约。而这部分字节码的意义就在于阻止用户在调用没有被 payable 标记的函数时,向该智能合约发送以太币。下面这张图是对这段代码进一步演算,左边两列分别是字节码和操作码,最右边一列是执行完该条语句之后栈的状态。

在上图中,前三句是将内存中从0x40开始往后 32 个字节的地址赋上0x60这个值,这是虚拟机保留的内存地址。后面的几句就是在通过查看发送的以太币是否为 0 来做 payable 检查。如果是 0 的话,那么虚拟机程序计数器(PC)跳转到0xe的位置继续执行,如果不是的话,终止程序。
在这里需要说明一下,stack 里面的每一个元素都是 32 字节长度,在这里为了方便,省略了高位的 0。
1.2 执行构造函数#
智能合约部署代码的第二部分是用来执行合约的构造函数的。如下图所示,在执行完这段字节码之后,heap 里面0x0的地址就被赋上了值0x1。0x0既是虚拟机为变量a在其 Wolrd State 里分配的地址。

在上图中,JUMPDEST对应上面的0xe,它代表了如果通过上面的 payable 检查,我们应该跳转到这里继续执行代码。SSTORE命令是用来将栈上的值存储到 World State 上的。在图中我用了 heap 来代表 World State 是因为它们俩有很多相似之处。我们知道在 Java 里面,栈是用来存储函数运行时的临时变量的,而堆是用来存储生命周期更长的变量,比如成员变量。栈上的数据会随着方法的执行完毕而被实时清空,而堆上的数据会在整个类实例的生命周期里面始终有效。Java 虚拟机不会将堆中的成员变量清空,除非该类的实例被回收。而一个部署到以太坊上的智能合约可以被认为是永远活着的合约实例(当然一个合约也可以被杀死)。所以用来存放智能合约状态的 World State 就可以被看做是以太坊的 heap。在这里我之所以用 heap 来代指 World State,第一是希望跟 stack 做一个呼应,第二是希望从另一个方面描述以太坊的本质:以太坊是一个计算机网络,它将整个网络里面的所有计算机连接起来形成一个单一计算机。在这个计算机中,它使用数据结构来模拟内存的工作机制从而实现图灵完备的编程语言。
在以太坊中,World State 是一个 key-value pair。每一个 key 对应一个 32 字节长的数据块。所以在上图所示的情况里面,0x0 这个 key 所对应的数据块里面存储了 0x1 这个数(32 字节,高位补 0)。
1.3 复制代码#
智能合约部署代码的第三部分是将剩余的代码,既智能合约本身的代码和 Auxdata 从 Transaction 中复制到内存里面并返回之。

从上图可知,我们将0x23到0x58的字节码(总共 0x35 个字节码)复制到了内存中0x0到0x35的地址上。
2. 智能合约本身的代码#
整个字节码的第二部分是智能合约本身的代码,它们会在智能合约的函数被调用的时候执行。因为在我们当前的例子中,智能合约只有一个构造函数,而没有其他方法,所以下图所示的代码并没有做什么有实际意义的操作。
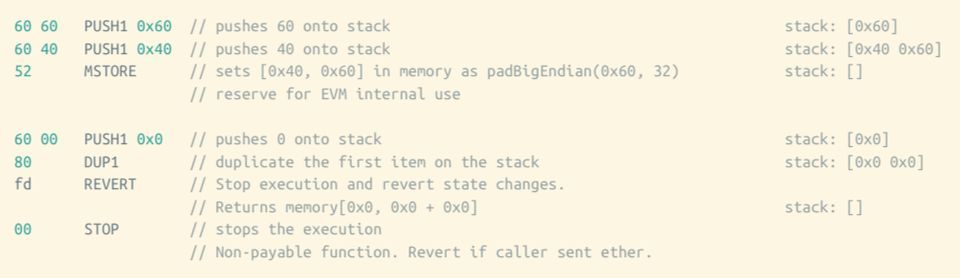
3. Auxdata#
第三部分 Auxdata 是有一个固定模板的:
0xa1 0x65 'b' 'z' 'z' 'r' '0' 0x58 0x20 ❤2 bytes swarm hash> 0x00 0x29我们将上述的字节码a165627a7a72305820d315875f56b532ab371cf9aa86a62850e13eb6ab194847011dcd641b9a9d2f8d0029带入该模板中,可以得到 swarm hash 为d315875f56b532ab371cf9aa86a62850e13eb6ab194847011dcd641b9a9d2f8d,这个 Swarm Hash 可以用来校验智能合约的代码,也可以用来获取智能合约的元数据。
创建合约的合约#
我们已经通过上面的讲解,了解了部署智能合约的整个流程。在这个流程中,字节码以 Transaction 的方式发送给以太坊从而完成对其的部署,不过智能合约不仅能被手动创建,也可以被其他已有的智能合约创建。
pragma solidity ^0.4.11;
contract Foo {
}
contract FooFactory {
address fooInstance;
function makeNewFoo() {
fooInstance = new Foo();
}
}在上面的代码里面我们可以看到两个合约,一个是 Foo,一个是用来创建 Foo 的 FooFactory。如果我们把上面的代码编译之后会得到如下的字节码:
FooFactoryDeployCode
FooFactoryContractCode
FooDeployCode
FooContractCode
FooAUXData
FooFactoryAUXData不难看出,整个字节码分两层,每一层又和之前描述的一样,分为三个部分。最外层的字节码用来部署 FooFactory,它的 Contract Code 部分是用来创建合约 Foo 的,所以在这一部分里面又嵌套了一套完整的用来部署合约的代码。
增加一个成员变量#
在第一个例子中,我们在整个合约里面只创建了一个成员变量。现在让我们来把合约变的复杂一点,再增加一个成员变量,看看相应的字节码有什么变化。
pragma solidity ^0.4.11;
contract C {
uint256 a;
uint256 b;
function C() {
a = 1;
b = 2;
}
}在省略掉其余部分之后,运行构造函数的部分如下所示:
5b JUMPDEST
60 01 PUSH1 0x1
60 00 PUSH1 0x0
81 DUP2
90 SWAP1
55 SSTORE // heap {0x0 => 0x1}
50 POP
60 02 PUSH1 0x2
60 01 PUSH1 0x1
81 DUP2
90 SWAP1
55 SSTORE // heap {0x0 => 0x1} {0x1 => 0x2}
50 POP很容易看出,虚拟机依次为变量a和b在 World State 中分配了两个地址0x0和0x1,并且赋上了相应的值 1 和 2。事实上如果有更多的成员变量,虚拟机会依次的为它们分配存储地址。在这里我们分配的存储地址对应于该RPC里面的第二个参数。
从 256 位到 128 位#
在上面的例子中我们声明了两个 256 位(32 字节)的无符号整型数。在实际运用中我们可能根本不需要那么多的空间,比如在其他语言中常用的整型数只有 4 个字节。所以现在让我们来做一点优化,把这两个 32 字节的数变成两个 16 字节的整型数,看看会发生什么变化。
pragma solidity ^0.4.11;
contract C {
uint128 a;
uint128 b;
function C() {
a = 1;
b = 2;
}
}同样的,将其余部分省略,运行构造函数的部分如下所示:
/********************** a = 1 ********************************/
60 01 PUSH1 0x1 stack: [0x1]
60 00 PUSH1 0x0 stack: [0x0 0x1]
80 DUP1 stack: [0x0 0x0 0x1]
61 0100 PUSH2 0x100 stack: [0x100 0x0 0x0 0x1]
0a EXP(base, exponent) stack: [0x01 0x0 0x1]
81 DUP2 stack: [0x0 0x1 0x0 0x1]
54 SLOAD(location) stack: [0x0 0x1 0x0 0x1]
81 DUP2 stack: [0x1 0x0 0x1 0x0 0x1]
6f ffffffffffffffffffffffffffffffff PUSH16 stack: [0xffffffffffffffffffffffffffffffff 0x1 0x0 0x1 0x0 0x1]
02 MUL(x, y) stack: [0xffffffffffffffffffffffffffffffff 0x0 0x1 0x0 0x1]
19 NOT stack: [0xffffffffffffffffffffffffffffffff00000000000000000000000000000000 0x0 0x1 0x0 0x1]
16 AND(x, y) stack: [0x0 0x1 0x0 0x1]
90 SWAP1 stack: [0x1 0x0 0x0 0x1]
83 DUP4 stack: [0x1 0x1 0x0 0x0 0x1]
6f ffffffffffffffffffffffffffffffff PUSH16 stack: [0xffffffffffffffffffffffffffffffff 0x1 0x1 0x0 0x0 0x1]
16 AND stack: [0x1 0x1 0x0 0x0 0x1]
02 MUL stack: [0x1 0x0 0x0 0x1]
17 OR stack: [0x1 0x0 0x1]
90 SWAP1 stack: [0x0 0x1 0x1]
55 SSTORE(pos, val) stack: [0x1]
heap: {0x0 => 0x1}
50 POP stack: []
/********************** b = 2 ********************************/
60 02 PUSH1 0x2 stack: [0x2]
60 00 PUSH1 0x0 stack: [0x0 0x2]
60 10 PUSH1 0x10 stack: [0x10 0x0 0x2]
61 0100 PUSH2 0x100 stack: [0x100 0x10 0x0 0x2]
0a EXP stack: [0x100000000000000000000000000000000 0x0 0x2]
81 DUP2 stack: [0x0 0x100000000000000000000000000000000 0x0 0x2]
54 SLOAD(location) stack: [0x1 0x100000000000000000000000000000000 0x0 0x2]
81 DUP2 stack: [0x100000000000000000000000000000000 0x1 0x100000000000000000000000000000000 0x0 0x2]
6f ffffffffffffffffffffffffffffffff PUSH16 stack: [0xffffffffffffffffffffffffffffffff 0x100000000000000000000000000000000 0x1 0x100000000000000000000000000000000 0x0 0x2]
02 MUL stack: [0xffffffffffffffffffffffffffffffff00000000000000000000000000000000 0x1 0x100000000000000000000000000000000 0x0 0x2]
19 NOT stack: [0x00000000000000000000000000000000ffffffffffffffffffffffffffffffff 0x1 0x100000000000000000000000000000000 0x0 0x2]
16 AND stack: [0x1 0x100000000000000000000000000000000 0x0 0x2]
90 SWAP1 stack: [0x100000000000000000000000000000000 0x1 0x0 0x2]
83 DUP4 stack: [0x2 0x100000000000000000000000000000000 0x1 0x0 0x2]
6f ffffffffffffffffffffffffffffffff PUSH16 stack: [0xffffffffffffffffffffffffffffffff 0x2 0x100000000000000000000000000000000 0x1 0x0 0x2]
16 AND stack: [0x2 0x100000000000000000000000000000000 0x1 0x0 0x2]
02 MUL stack: [0x200000000000000000000000000000000 0x1 0x0 0x2]
17 OR stack: [0x200000000000000000000000000000001 0x0 0x2]
90 SWAP1 stack: [0x0 0x200000000000000000000000000000001 0x2]
55 SSTORE stack: [0x2]
heap: {0x0 => 0x200000000000000000000000000000001}
50 POP stack: []总得来讲上面的代码分为两个部分,第一部分对应a = 1,这部分代码在地址0x0的低 16 字节里存入0x1;第二部分对应b = 2,它表示在 0x0 的高 16 字节里面存入 0x2. 所以在运行完上面的代码之后,我们只使用了 World State 里面的一个 key,即0x0,完成了对两个变量的保存。 用更形象的方式可以表示成:
[ b ][ a ]
[16 bytes / 128 bits][16 bytes / 128 bits]打包存储#
那么问题来了,为什么虚拟机要做这个变动?这两个例子的 Solidity 代码几乎一样,我们只是改变了变量的类型而已,然而虚拟机为第二个例子编译出的字节码比之前例子的字节码长了不止一倍。要知道,这些增加的字节码可是会直接影响 Transaction 的大小的。所以虚拟机到底是出于何种目的来产生了如此多的字节码的呢?
其实对于上面的问题有一个简单的答案,那就是 gas。我们知道执行、部署合约是需要消耗 gas 的,而具体到 EVM 的层面,那就是每个操作码都有其对应的需要消耗的 gas。下面是对一些操作码消耗 gas 的说明:
sstore当使用这个操作码往一个新的地址中存入数据时消耗 20000 gassstore当使用这个操作码往一个已有的地址中存入数据时消耗 5000 gassload当使用这个操作码从 World State 中读取数据,消耗 500 gas- 其余的操作码消耗 3 到 10 gas
所以在两个例子中我们消耗的 gas 分别为:
- 20000 + 20000 = 40000
- 500 + 20000 + 5000 + 500 = 26000
在打包存储的情况下,因为我们第二次使用sstore时,只是往已有的地址中再次写入数据,所以我们省掉了 15000 的 gas。正是由于这个原因,虚拟机才宁愿编译出如此复杂的字节码,也不愿意直接使用来个存储地址。
编译优化#
其实上述字节码还是略显冗长,因为很容易想到,我们其实可以在内存里面先准备好a和b对应的数据,然后在一次性的存到 World State 里面,这样一来我们还可以再节省掉第二个sstore所消耗的 5000gas。我们可以通过指示编译器优化字节码的方式来达到这个目的。在之前讲到的编译工具里面,让编译器优化代码的方法分别为:
solc --bin --asm --optimize file_name.sol- http://remix.ethereum.org 勾选
enable-Optimization选项
我们现在再进行一次编译,看看结果会如何
60 00 PUSH 0x0
80 DUP1
54 SLOAD
70 0200000000000000000000000000000000 PUSH17
/* not(sub(exp(0x2, 0x80), 0x1)) 高16字节bitmask */
60 01 PUSH 0x1
60 80 PUSH 0x80
60 02 PUSH 0x2
0a EXP
03 SUB
19 NOT
90 SWAP1
91 SWAP2
16 AND
60 01 PUSH 0x1
17 OR
/* sub(exp(0x2, 0x80), 0x1) 低16字节bitmask */
60 01 PUSH 0x1
60 80 PUSH 0x80
60 02 PUSH 0x02
0a EXP
03 SUB
16 AND
17 OR
90 SWAP1
55 SSTORE从上面我们可以看出,虚拟机通过使用 bitmask 分别将高 16 字节和低 16 字节赋值,而且只使用了一个sstore指令就像数据存入了 Worl State 里面。优化目的达成!
但是,等等,为什么要在字节码中直接嵌入0200000000000000000000000000000000这 17 个字节?要知道我们只需要做一个简单运算便能获得这个值:exp(0x2, 0x81)。 换句话说,我们其实只需要用 3 个字节就能代表这 17 个字节,但是虚拟机为什么没有这么做呢?答案很简单,仍然是 gas。让我们来看看每个字节消耗 gas 的规则:
- 每一个 0 字节消耗 4 个 gas
- 每一个非 0 字节消耗 68gas
根据这个规则,我们很容易计算出两种情况下消耗的 gas 的值:
- 68 + 16 x 4 = 132
- 68 x 3 = 204
所以直接嵌入0200000000000000000000000000000000虽然显得笨拙,但是贵在便宜。虚拟机宁愿增加字节码的大小也想为用户节约每一个 gas。
总结#
好了,讲了这么多,让我们来回顾一下,做个总结。
- 智能合约的生命周期被严格的划分为两个阶段:部署时和运行时。
- 智能合约的构造函数在且仅在部署时运行,一旦被部署就不可能再次运行构造函数了。
- World State 是一个键值对,每一个键对应一个 32 字节长的数据块。
- 因为上面一点,以太坊虚拟机是一个 256 位机,其天生就是用来对 32 字节长的数据做运算的。
- 往 World State 里面存数据是非常昂贵的。
- 以太坊虚拟机一切向钱看,所有的优化都是围绕减少所需 gas 而进行的。
下期预告#
我们已经知道了没有参数的构造函数是怎么以字节码的形式执行的了,那么有参数的构造函数呢?部署完一个合约之后,怎么调用其上的函数呢?什么是 ABI Encoding?在下一期深入讲解 EVM 的博客中,我们会一一为你解答这些问题。